Kafka BlueGreen Deployment
One of the most challenging and tedious tasks that as a developer I faced, has been about software/hardware upgrades in a production Kafka cluster. During my work for the EPS(Expedia Partner Solutions) data lake I used different approaches to solve this problem.
The first approach I took was to make partial updates of the cluster and then doing reassignment of partitions. This approach involves batch updates of the production cluster:
- Move all the traffic from one batch of nodes to the rest of nodes(the intact ones). For doing this you have to use a Kafka command to reassign partitions.
- Update the batch while the rest of the nodes keeps intact and all the traffic has been redirected to them.
- Do the same with the rest of the batches, reassigning partitions and installing the new software/hardware.
As you see this process is quite tedious and dangerous. One of the consequences of this approach is that the Kafka cluster would have more load and it would incur into several topic rebalances.
For example, imagine that you have a production Kafka cluster of 100 brokers. Maybe you have to use update batches of 10 nodes for not affecting the incoming Kafka traffic. This process would involve 10 reassignment of partitions and 10 batch updates.
All the information about how to make a Kafka deployment using a batches update can be found here.
BlueGreen Kafka Deployment
The BlueGreen deployment technique consists on creating a group of new instances and whenever the new instances are ready switch the traffic over.
The following diagram shows the architecture to implement.
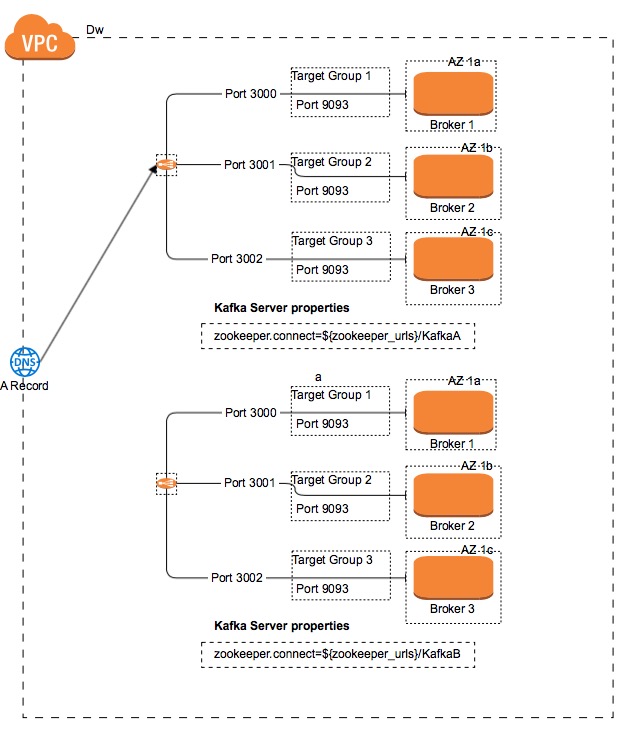
The main idea behind it is to have two Kafka Clusters running in parallel and switch the traffic from the Route53 DNS record to point to the new cluster.
The old cluster is not removed immediately. It is required to wait until all the traffic from the producers has been switched and all the consumers have processed all the topics. This means that for all the topics in the old Kafka cluster there is zero lag.
We will go more in detail explaining how to implement and check all of the different parts.
Why not to use AWS CodeDeploy
AWS CodeDeploy has an option to make BlueGreen deployments. It allows to deploy a new version of your code/application without affecting users. So, it deploys the code in new instances and once all the instances are ready it unsubscribes the old instances from the load balancer and subscribes the new instances to the autoscaling group.
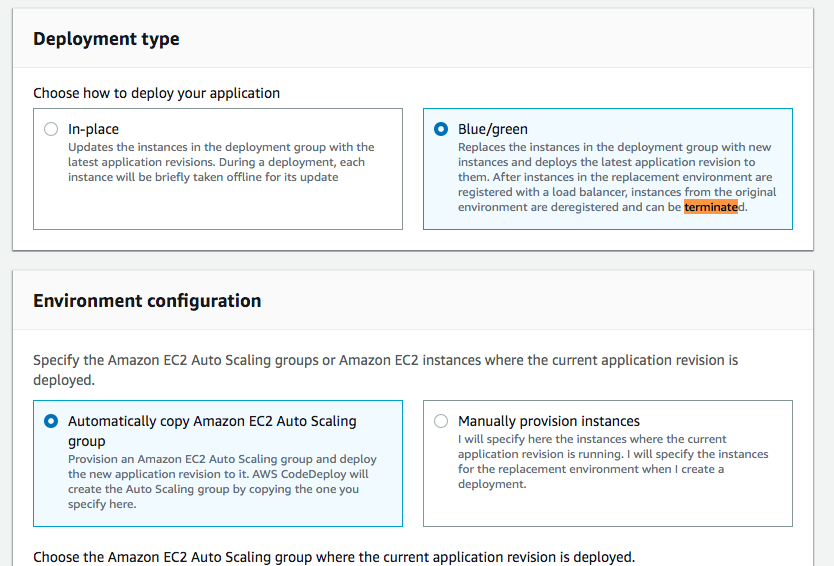
Once the instances are being deregistered from the load balancer, you can choose to terminate them or keep them.
Code deploy works fine when a new version of the application is being deployed. The BlueGreen deployment really does what it is expected, but in case of hardware changes CodeDeploy BlueGreen deployment is not helping much.
The way that AWS CloudFormation works when there is an Autoscaling launch configuration update, it’s just killing the instances and creating new ones. And obviously this is something that is not acceptable in a stateful service like Kafka.
Code deploy is a really interesting tool provided by AWS and I will write about it in a future post to explain all the capabilities of it: deployment configuration(all at once, one by one …), rollbacks…
BlueGreen implementation
It is required to deploy a new Kafka Cluster in production. In our case the decision taken was to maintain the same codebase. For being able to deploy two different Kafka clusters in production with the same CloudFormation codebase, we modified our CF code to include a function suffix in the name of all of our resources.
Kafka has a direct dependency with Zookeeper. Zookeeper contains information about the partitions, brokers, partition leaders… Obviously the zookeeper connect url has to be different between the two Kafka clusters. The only thing that needs to be changed is the property zookeeper.connect inside of the server.properties:
zookeeper.connect=${zookeeper_urls}/KafkaA
Zookeeper allows to use the same Zookeeper cluster by different Kafka clusters. The only thing that has to be modified is the Path at the end of the zookeeper connection.
The following diagram shows the architecture of a Kafka Cluster.
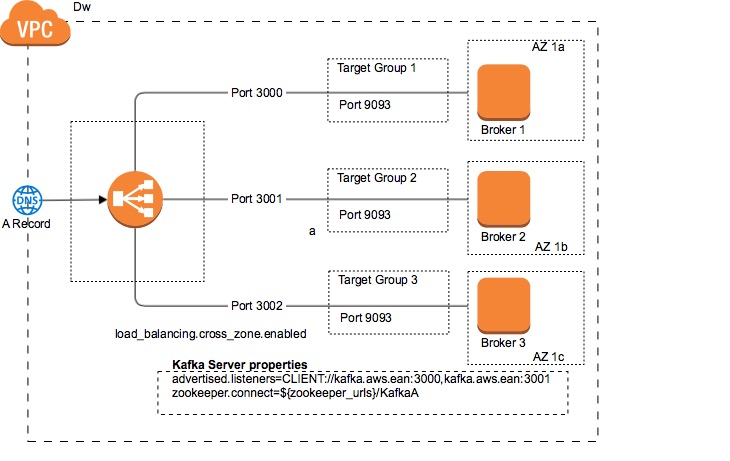
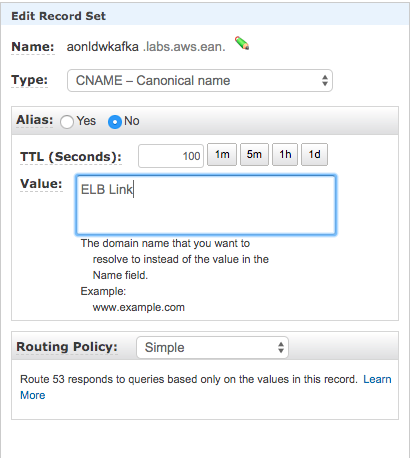
As you can see there is a load balancer that balances the traffic across all the Kafka brokers. There is as well a Route53 DNS record that points to the Network Load Balancer. For switching the traffic for one cluster to another, just change the Route53 DNS endpoint to point to the new Kafka Cluster Load Balancer. Check out the following diagram:
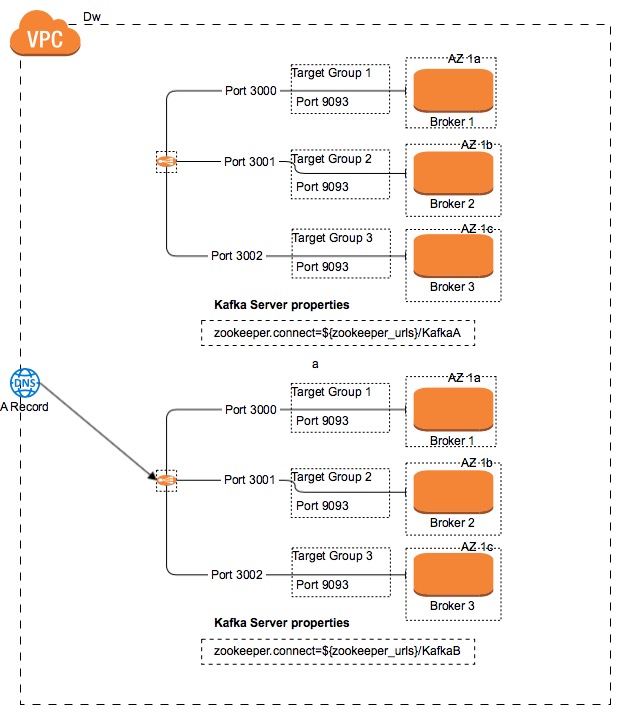
It is important to setup the Route53 TTL property accordingly. The Time To Live property allows clients maintain cached the route53 endpoint IP address for a time. If the TTL property is set to 10 minutes, in case of a DNS endpoint change, it won’t be effective at least until the TTL has been expired:
Producer Code changes
Normally the Kafka producers do not create a new connection to Kafka every time they send a new record to Kafka. Normally producers they implement a singleton pattern, defining at the creation of the service a KafkaClient instance. With this kind of producer implementation, even if the DNS endpoint has been switched to the new Kafka cluster, clients are not aware of this change, unless they restart/redeploy their services.
It is being required to create an implementation that in a scheduled thread creates a new Kafka client connection.
public class BlueGreenKafkaProducer{
scheduledService = Executors.newScheduledThreadPool(1);
runnable = new BlueGreenKafkaSwitcher(refreshTime, this);
scheduledService.scheduleAtFixedRate(runnable, INITIAL_DELAY, PERIOD, TimeUnit.MILLISECONDS);
protected void switchBlueGreen(){
if(inUse == null){
logger.info("Initializing Blue Kafka Producer");
blue = new KafkaProducer(producerProperties);
inUse = BlueGreenKafkaEnum.BLUE;
}
else{
logger.info("Kafka Producer Switch");
if(inUse == BlueGreenKafkaEnum.BLUE){
logger.info("Switching from Kafka Producer Blue to Green");
green = KafkaProducer(producerProperties);
blue = null;
inUse = BlueGreenKafkaEnum.GREEN;
}
else{
green = null;
logger.info("Switching from Kafka Producer Green to Blue");
blue = new KafkaProducer(producerProperties);
inUse = BlueGreenKafkaEnum.BLUE;
}
}
}
}
Considerations about the previous code:
- In the line 2 it is being created a new Scheduled Thread.
- The line 3 define the Runnable object that will contain the logic to switch the Kafka Client
- In the line 4 it is defined the scheduled rate.
- From the line 7 it is defined the switcher. This method is being called by the the Runnable instance that will make the BlueGreen switch.
public class BlueGreenKafkaSwitcher implements Runnable {
private final Logger logger = LoggerFactory.getLogger(BlueGreenKafkaSwitcher.class);
private BlueGreenKafkaProducer bluegreen;
public BlueGreenKafkaSwitcher(Duration refreshTime, BlueGreenKafkaProducer bluegreen) {
this.bluegreen = bluegreen;
}
public void run() {
bluegreen.switchBlueGreen();
}
}
Considerations about the previous code:
- In the line 11 this runnable instance will call for the bluegreen switch.
Conclusions
Doing a Kafka BlueGreen deployment it is not complicated, but it has lot of moving parts. There are two well defined parts: infrastructure and producer library.
And the most important part is not losing data. So it requires creating a new Kafka infrastructure(Kafka Cluster and Connectors) and doing full End-to-End tests.
